


주제 6 난독화된 의료 영상의 원본 매칭

Scientific overview (연구 배경 및 중요성)
Recent advancements in machine learning and artificial intelligence (AI) have placed individual privacy, especially in sectors such as medical imaging, at the forefront of discussions. The potential of data containing personal identifiers necessitates rigorous measures to ensure the privacy and security of medical information.
To address this, several techniques like server-to-client encryption, federated learning, and homomorphic encryption have been proposed. A notable approach is data obfuscation, which involves rendering the data too ambiguous to understand or capture the information from the data.
The objective of data obfuscation is to remove personal information in medical image data so that people cannot recognize any details to identify private or sensitive information from the data, while preserving the utility of the data for machine learning to achieve highly accurate medical diagnoses.
Additionally, such an obfuscated private data representation should be secure against attacks from adversarial actors who attempt to breach a user’s privacy or uncover an identity by reconstructing original images from the obfuscated images.
Challenge questions (문제 정의)
Assume that you are an adversary aiming to identify the original images corresponding to a given obfuscated image. Your challenge is to accurately link obfuscated images to their originals using any algorithmic strategies, including machine learning.
Data description (데이터 설명 – 데이터 셋 구성, 형식, 특징)
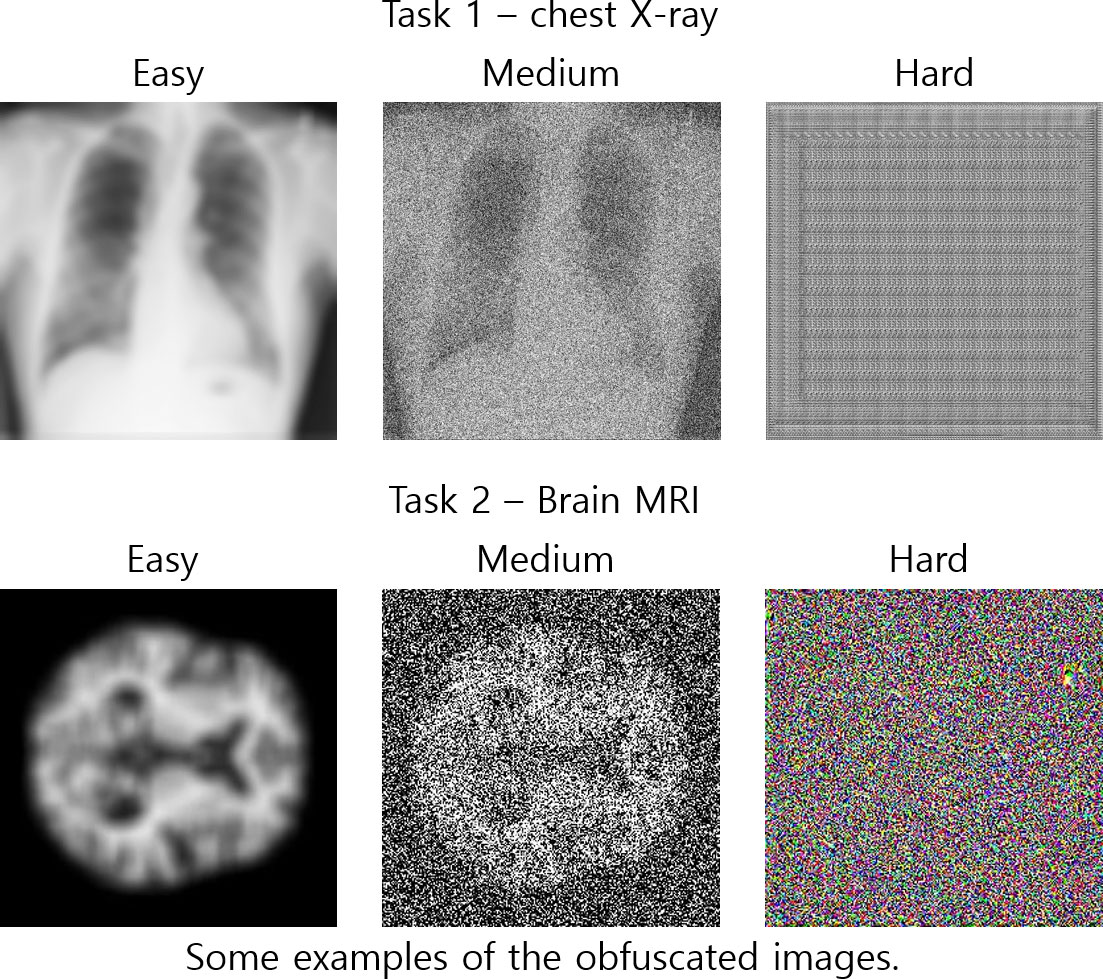
For each task, participants are presented with 500 obfuscated images Z and a pool of 10,000 candidate original images X. Each obfuscated image z∈Z is the output of the (unknown) obfuscation algorithm O(x)→z derived from an image x ∈ X.
-
Task 1. Chest X-ray : Candidate images are randomly drawn from a publicly available chest X-ray dataset, consisting of 25,484 grayscale images of size 1024x1024.
O was trained on the National Institute of Health (NIH) Chest X-rays dataset. The dataset is comprised of 112,120 frontal-view X-ray grayscale images of size 1024x1024 from 30,805 unique patients. It includes 14 common disease labels, mined from the respective radiological reports. - Task 2. Brain MRI : O was trained on the OASIS-1 brain MRI dataset. The dataset consists of a cross-sectional collection of 416 subjects aged 18 to 96. For each subject, 3 or 4 individual T1-weighted MRI scans obtained in single scan sessions are included. The subjects are all right-handed and include both men and women. 100 of the included subjects over the age of 60 have been clinically diagnosed with very mild to moderate Alzheimer’s disease. We use the preprocessed images included in its public distribution, which has been gain-field-corrected, registered to the atlas according to Talairach coordinates, and masked so that the intensity of all nonbrain voxels set to zero. From each sample, 20 slices are selected based on their entropy values.
For the original images of Task 1. Chest x-ray, the NIH Clinical Center is the data provider.
- • A link to the NIH download site: https://nihcc.app.box.com/v/ChestXray-NIHCC/
- • A citation to the CVPR 2017 paper: Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mohammadhadi Bagheri, Ronald Summers, “ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases”, IEEE CVPR (2017), pp. 3462-3471.
For the original images of Task 2. Brain MRI, data were provided by OASIS-1.
- • A link to the OASIS download site: https://www.oasis-brains.org/
- • OASIS-1 source info: Cross-Sectional: Principal Investigators: D. Marcus, R, Buckner, J, Csernansky J. Morris; P50 AG05681, P01 AG03991, P01 AG026276, R01 AG021910, P20 MH071616, U24 RR021382
- • A citation to the OASIS publication: OASIS-1: Daniel S. Marcus, Tracy H. Wang, Jamie Parker, John G. Csernansky, John C. Morris, Randy L. Buckner, “Open Access Series of Imaging Studies (OASIS): Cross-sectional MRI Data in Young, Middle Aged, Nondemented, and Demented Older Adults”, Journal of Cognitive Neuroscience (2007) 19 (9): 1498–1507.
Evaluation matrix (정량적 평가 방법)
The core query is, “How feasible is it for an adversary to determine the correspondence between original and obfuscated images?”
We measure this feasibility using guesswork, i.e., the number of guesses required for an adversary to match a single original image to its corresponding obfuscation.We measure this feasibility using guesswork, i.e., the number of guesses required for
an adversary to match a single original image to its corresponding obfuscation.
The participants should aim to simulate the best effort attacker and are expected to submit a
csv file containing indexes of \((z, X_p)\) for each \(z∈Z\), where \(X_p\) is a sequence of \(x\) sorted by
the predicted likelihood of \(x\) being the original version of \(z\). Given \((z, X_p)\), guesswork is measured as
Guesswork\((z,X_p)\) = Index of \(x^*\) in \(X_p\) , where \(O(x^*)\) = \(z\).
The lower the guesswork, the closer the participant is to the best effort attacker.
The final ranking will be determined based on the mean of guessworks about total 1000 cases (=2 tasks x (100 easy cases + 200 medium cases + 200 hard cases)).
